Physical Address
304 North Cardinal St.
Dorchester Center, MA 02124
Physical Address
304 North Cardinal St.
Dorchester Center, MA 02124


”
不知道你们发现没有,最近打开任何科技媒体的头条,AI相关的讨论简直像潮水一样涌来。特别是我们做SEO这行的,茶余饭后的话题十有八九都绕不开生成式AI——从ChatGPT到Bard,这些工具每周都有新突破,搞得我们这些老SEOer都得重新思考工作流程了。

我最近在行业论坛里看到不少同行都在说,以前做了十几年的内容优化套路,现在被AI搞得有点措手不及。有个做独立站的朋友跟我吐槽,说他精心维护的技术博客,现在可能正在给Google的AI模型当「养料」。这让我突然想起华盛顿邮报之前曝光的那个C4数据集,据说收录了上千万个网站内容来训练AI,但具体用了谁的、用了多少,普通站长根本无从得知。
说来也巧,上周我试着查了下自己的小破站,结果发现居然被用了280多个token。你说该高兴还是该担心呢?毕竟这些内容就像自己养大的孩子,突然被拿去当训练素材,连声招呼都不打。现在连Bing都知道标注部分内容出处,但Google这边就像个黑箱…
这波AI浪潮真是来得又快又猛!不过话说回来,你们有没有想过自己的网站内容可能正在「喂养」这些AI模型?要是哪天发现自己的原创文章成了AI的「口粮」,你会选择在robot.txt里加上禁止指令吗?反正我现在是既期待又有点小纠结啊。
从业这些年有个很深的感受,搜索引擎优化这行当的核心玩法其实二十多年没怎么大变过。记得2003年刚接触SEO那会儿,我们整天琢磨的不外乎三件事:怎么产出优质内容、怎么让爬虫顺利抓取、怎么确保用户访问体验。就像给网站做体检似的,反反复复检查标签、调整链接结构、优化页面加载速度,这套流程估计老SEOer们都熟得能背出来。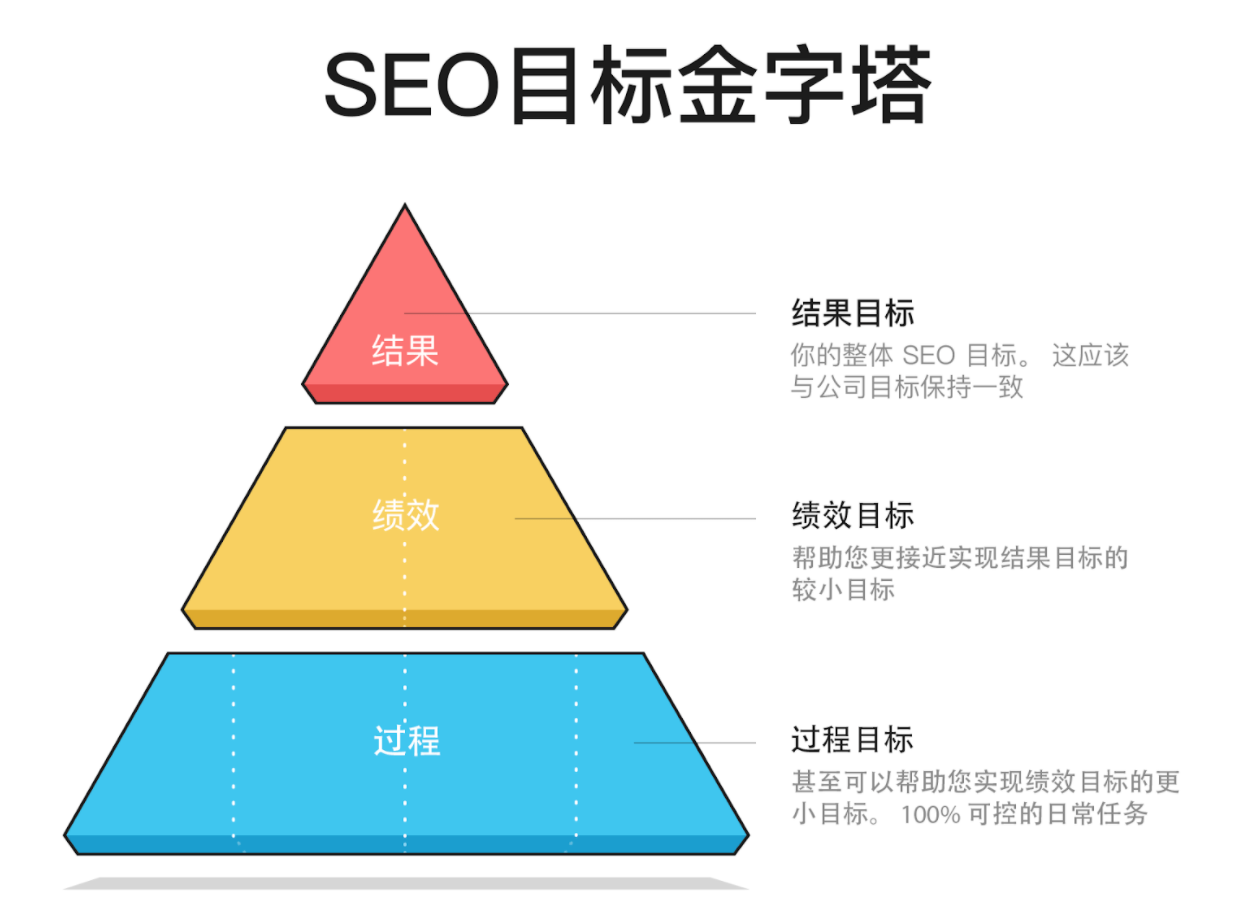
不过最近几个月行业里都在传,说ChatGPT这类AI工具可能要改写游戏规则了。你发现了吗?现在Google测试的生成式AI搜索结果,压根不标注内容出处,这跟我们熟悉的传统搜索呈现方式完全两码事。要是哪天用户直接在AI生成的答案里找到想要的信息,谁还愿意点进原始网站?这算不算行业的一个转折点呢?
我最近在琢磨,咱们以前那些SEO技巧,比如关键词布局、外链建设这些,放在AI时代还管用吗?举个实际的例子,以前为了长尾词排名,可能要专门做内容矩阵,现在AI分分钟能生成上百篇相关文章。这倒逼着我们得重新思考内容策略——是不是应该更侧重原创深度分析?或者加强知识产权的保护?大家不妨在评论区聊聊,你们团队最近调整SEO策略了吗?
这两天和几个站长朋友聊天,大家都在讨论一个挺有意思的现象——现在连搜索引擎都学会当『文抄公』了。上回咱们聊到Google正在测试的生成式AI功能,不知道你们注意到没有,它给出的答案里压根找不到内容出处。这让我突然想起个事,要是哪天我的原创文章被AI拿去当训练素材,最后连个署名权都没有,那我可要掀桌子了!
说实话,我之前还专门翻过《华盛顿邮报》那个网站查询工具,发现自己的博客居然被用了好几百个token。虽然有点小自豪,但转念一想,这就像你辛辛苦苦种的菜,邻居家AI机器人天天来摘,连声谢谢都不说。你说这是不是有点不厚道?
现在Bing那边好歹还会标注部分内容来源,但Google这边就跟个黑箱子似的。要是他们真打算这么玩,我可能得考虑在robots.txt里给Google蜘蛛贴个『禁止入内』的告示。不过话说回来,咱们普通站长怎么才能知道自家内容有没有被拿去训练AI呢?难不成要像侦探似的天天盯着行业动态看?
建议大家有空也去查查自家网站的情况,说不定会有意外发现。就像我前几天发现,连知乎这种大平台在Google的C4数据集里都排不上号,可见他们的训练素材库水有多深。要是你发现自己辛苦创作的内容正在给AI做嫁衣,你会怎么做?反正我现在是既想被AI『看得起』,又怕它『吃干抹净』,这个矛盾劲儿啊…
不知道大家有没有和我一样的困惑——我们辛辛苦苦写的网站内容,到底有没有被拿去训练AI了?这个问题就像在问天上的云朵明天会变成什么形状,因为生成式AI给出的答案都是经过深度学习的原创内容,根本找不到直接对应的原文出处。
我最近在研究AI内容生成时发现个有趣现象,就算AI的答案和某篇网站文章观点相似,你也无法像传统搜索引擎那样点击「引用来源」去验证。这种黑箱操作,就像有人用你的食材做了道新菜,但完全改变了烹饪方式,让你根本尝不出原来的味道。

前阵子看到《华盛顿邮报》出了个AI训练数据查询工具,我兴冲冲去查自己博客,结果发现居然被用了280个token!这让我既欣慰又纠结——就像发现自家后院种的苹果被拿去做成果酱,虽然没直接偷苹果,但总感觉哪里怪怪的。
话说回来,你们有没有试过去Google的C4数据集查自己的网站?我有个做独立站的朋友查完当场懵了,他的产品说明文档居然被用了上万个token。要我说啊,现在做网站就像在沙滩上写字,不知道什么时候浪(AI)就把它卷走重组成新的图案了。
不知道你们注意到没有,Bing的AI搜索结果现在会像贴心小秘书一样标注部分内容出处,这可比以前透明多了。反观Google的生成式AI,就像个闷葫芦,压根不告诉你它说的内容是从哪个网站学来的。我最近发现华盛顿邮报搞了个特别实用的网站自查工具,输入自己的域名就能查到你家的内容有没有被Google拿去训练AI,这可比猜谜游戏靠谱多了!

说实话,这种差异挺有意思的。Bing那边虽然也不是所有内容都标出处,但至少能看到些来源链接,就像在超市买东西能看到生产日期。而Google这边完全是个黑箱,我们这些做网站的就像在玩「内容盲盒」——根本不知道自家文章是不是被拿去当AI的教材了。
这里给各位站长提个醒:赶紧用邮报那个工具查查看,说不定会有意外发现。我之前查自己的小破站,发现居然有280个token被收录,这感觉就像在图书馆发现自己的日记本被摆上了书架——既有点小骄傲,又担心隐私问题。
你们有没有想过,要是哪天Google的AI直接把你网站的核心内容换个说法呈现,用户还会点进你的网站吗?这个问题,值得每个内容创作者好好琢磨琢磨。
要说现在AI训练数据的来源啊,那可真是海纳百川。就拿Google的C4数据集来说吧,这个相当于AI的”营养食谱”,收录了超过1500万个网页内容。记得前阵子看《华盛顿邮报》的深度报道吗?他们专门开发了个可视化工具,能查特定网站在数据集里的出现频次,就像给网站做AI训练量的”体检报告”。
 我自己试着查了查,发现像维基百科这类大站的token数都是百万级起步,简直像AI的”主粮”。不过有意思的是,有些个人博客的数据量也不容小觑,这让我突然意识到——我们平时写的东西,说不定正在默默”喂养”着AI呢!
我自己试着查了查,发现像维基百科这类大站的token数都是百万级起步,简直像AI的”主粮”。不过有意思的是,有些个人博客的数据量也不容小觑,这让我突然意识到——我们平时写的东西,说不定正在默默”喂养”着AI呢!
说到这儿,你们有没有想过自己的网站可能也在训练AI?虽然Google从没公开完整名单,但通过C4数据集的冰山一角,我们已经能看到AI学习材料的庞大规模。下次更新网站时,或许该多问自己一句:我愿意成为AI成长的养料吗?
最近研究AI训练数据时发现个有意思的现象,Google用的那个C4数据集啊,就像餐厅的食材清单——标榜用的是有机蔬菜,其实后厨还有其他进货渠道。就拿知乎来说吧,这个中文互联网的知识宝库,在C4里居然踪迹难寻,你说奇怪不奇怪?

有技术宅朋友扒过数据,发现Google训练AI时对不同网站的『投喂量』差异巨大。像某些新闻网站被用了几十亿个token,相当于把整个图书馆都塞给AI学习,而普通博客可能就几百个token,就像往AI嘴里塞了块小饼干。
我自己用华盛顿邮报那个工具查了下,发现我的技术博客居然也被用了280个token。这感觉就像在AI的脑子里找到自己写的便签纸,既欣慰又有点细思极恐——你说这些碎片化的内容,会被AI拼凑成什么样呢?
更值得玩味的是,现在连专业机构都说不清Google到底用了哪些数据训练AI。这就好比你去餐馆吃饭,菜单上写着『秘制配方』,鬼知道后厨加了什么佐料。所以问题来了:你的网站内容正在被怎样使用?这恐怕要成为每个站长的新必修课了。
话说回来,现在想完全阻止内容被AI学习,就像试图用手挡住瀑布——不是说做不到,但真的费劲。与其被动挨打,不如主动了解这些游戏规则。下次更新robots.txt时,可能要考虑要不要加个Disallow: /AI-training/之类的声明了,你说呢?
当我用华盛顿邮报的网站检测工具查自己博客时,发现居然有280个token被收录进AI训练数据集,这感觉就像发现自家院子里种的苹果被摘去酿酒——既有点小骄傲又忍不住纠结。 看着这个数字,我突然想起邻居老王常说的那句话:’数据时代,我们都是数字农民’。这些被算法’收割’的文字碎片,既证明我的内容被AI系统认可,又让我忍不住担心——如果哪天我的文章被训练成完全相反的结论,那岂不是要闹大笑话?
看着这个数字,我突然想起邻居老王常说的那句话:’数据时代,我们都是数字农民’。这些被算法’收割’的文字碎片,既证明我的内容被AI系统认可,又让我忍不住担心——如果哪天我的文章被训练成完全相反的结论,那岂不是要闹大笑话?
最近在SEO交流群里看到个有意思的比喻:网站内容被AI训练就像参加’数字献血’,你永远不知道你的’数字血液’会流向何方。这种既想贡献智慧又怕被滥用的矛盾,相信很多内容创作者都深有体会。话说回来,你们有查过自己网站的token使用量吗?查完是觉得赚到了还是后背发凉?
当我发现自己的博客内容被Google用于训练AI时,内心其实挺矛盾的。就像发现自己种在后院的苹果被邻居摘走做成果酱,虽然没造成直接损失,但总感觉哪里不对劲——特别是当对方连张感谢卡都没寄的时候。
最近用工具查了下,我的文章居然被用了近300个token。这数字说大不大,但联想到某些大平台动辄上亿的数据采集量,突然意识到我们每个站长的内容可能都在默默喂养着AI巨兽。
不知道你们有没有想过,当我们在深夜赶稿的时候,那些原创内容可能正在变成AI模型的训练饲料?华盛顿邮报那个网站检测工具真的值得一试。我试过后才发现,原来自己网站的内容权重,在AI眼里可能还不如某些论坛的水贴——这感觉就像精心准备的料理被当成预制菜原料。
现在每次更新博客时,总会多问自己一句:如果这些文字最终只是帮AI变得更聪明,而创作者连个署名权都得不到,这样的『知识共享』真的公平吗?特别是看到某些平台的AI回答明显『借鉴』了我的原创观点,却没有任何溯源信息时…
建议大家有空都去查查自己的网站数据,毕竟这是关乎数字时代创作尊严的事。你的内容值得被尊重,而不是无声无息地消失在AI的黑箱里——就像我们不应该默默接受超市把自家菜园的蔬菜标成『产地不详』那样。